mpiku, to spojujes nekolik problemu. Dulezite je, kde koukas na poradi nalezu (jak je to poradi sestaveno).
Stator ma pracovni tabulku, ktera obsahuje nalezy razene podle takovych kriterii, jaka si uzivatel zvolil. Pri te volbe by mely byt zohledneny zvyklosti uzivatele:
- pokud vzdy zadava cas nalezu, je vhodne tento cas pouzit jako radici kriterium a pak nemuze byt poradi spatne
- pokud neni cas zadavan vubec, je zbytecne jej jako kriterium pouzit a je vhodne pouzit ID logu. To ovsem vyzaduje sprave poradi logovani
- pokud je nekdy cas zadan a jindy ne, pak se domnivam, ze spravne poradi bude pri stejnem nastaveni jako v prvnim pripade
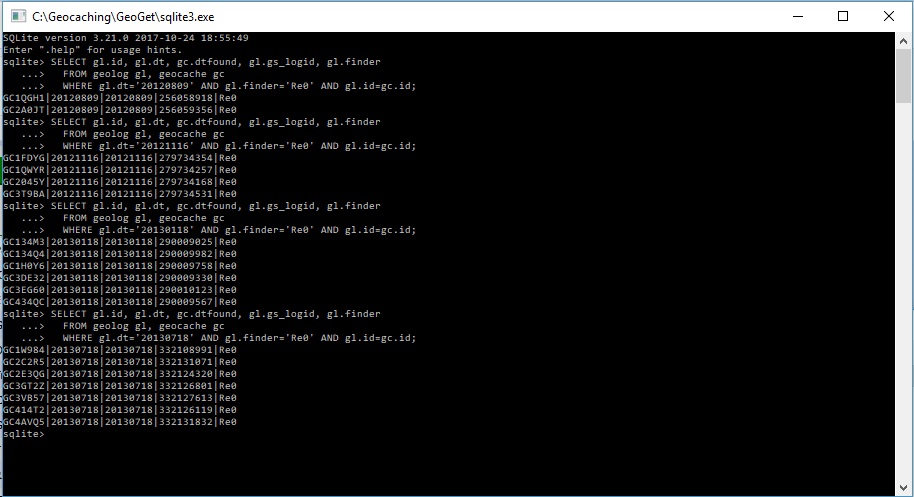
To se ale bavim o pracovni tabulce! Pokud nejaky modul pouziva vlastni SQL, kde jsou kriteria razeni zakleta primo do toho SQL a nebere se v uvahu poradi v pracovni tabulce, je to jeho vec a je treba jej upravit. Nebo pouzit takove SQL, ktere pouzije pracovni tabulku. Pro vyse uvedeny pripad Prvni kese ve state vypada to SQL takto:
select num, country "Country flag, text", dtfound "Found date=Right", id, cachetype "Type icon", Name FROM
(SELECT st.rowid as num, country, dtfound, st.id, cachetype, name
-- v pracovni tabulce jsou jen nalezy a jsou spravne serazene
FROM temp.Stator st, geocache gc
WHERE st.id=gc.id
ORDER BY st.rowid desc
)
GROUP BY Country
ORDER BY dtfound
Pracovni tabulka obsahuje jen nalezy a ty jsou serazene spravne (tedy podle kriteria, ktere si urcil uzivatel s ohledem na sve praktiky). To byl hlavni duvod pro jeji vytvoreni - zrychlit a zjednodusit jine dotazy pracujici s nalezy. Proto by mel byt tento SQL take podstatne rychlejsi nez SQL, ktere pracovni tabulku nepouzivaji (viz predchozi prispevky).

 Toto téma je zamknuto
Toto téma je zamknuto

















 GeoGet
GeoGet
 URWIGO
URWIGO
 CWG
CWG


